While cryptocurrency exchanges have been offering various kinds of delta one derivatives for a number of years now (such as perpetual futures), the availability of vanilla European call/put options (let alone more complex derivatives) is still nascent. Understandably, traders entering the crypto space would like access to the same tools that they are used to in more traditional and developed markets. Even Goldman Sachs is onboard with the development of a bitcoin options market. Yet, the high volatility of cryptocurrencies produces some unique challenges for the creation of derivatives markets.
See also our main article on cryptocurrency consulting services.
Perpetual futures contracts
Perpetual futures (also called perpetual swaps) on crypto underlyings like Bitcoin are a derivative product first offered by Bitmex and now offered by many cryptocurrency exchanges. Cryptocurrency exchanges typically offer them with up to 100x leverage. While they are similar in some ways to ordinary futures contracts, there are some significant differences.
Firstly, and giving rise to the name, they have no expiry and can instead be closed out at any time by the holder. They could also be closed out by the exchange if the holder gets liquidated, which we’ll discuss shortly.
Secondly there is a mechanism called the funding rate. In an ordinary futures market, the futures price is always related to the spot price. This is ensured by the fact that the futures price converges to the spot price as time approaches the expiry. Since a perpetual futures market has no expiries, this characteristic, if desired, must be created artificially. The funding rate is set by the exchange and is used to ensure the futures price does not diverge too far from the spot market. It is paid directly between market participants and not to the exchange. When the futures price is above the index price, the rate is positive, and traders long perpetual futures must pay the funding rate to those who are short. When the futures price is below the index price, the rate is negative, shorts must pay longs. Note that the index price here could be a weighted average of the spot price among multiple exchanges. In many cases the funding rate is paid every eight hours.
Bitmex also offers a so-called inverse perpetual futures contract.
Perpetual options
Perpetual options are similar to perpectual futures, except that one replaces the futures payoff with that of a call option or put option. See our main article on perpetual options.
Liquidation
The high volatility of cryptocurrencies combined with the high leverage offered by many exchanges creates challenges for the operation of margin accounts. Because of this, crypto exchanges tend to liquidate positions well before the participants actually run out of margin. If they are able to close out the position at better than the bankruptcy price, this extra money goes into an insurance fund. This is a buffer the exchange uses to ensure it is able to pay traders who have profited from price moves.
Options – calls and puts
Cryptocurrency exchanges are increasingly interested in branching out into options. While some exchanges already offer versions of European and American call/put options, other exchanges are rapidly trying to develop them. More exotic options such as barrier options and Asian options will presumably become common eventually.
It’s well-known that vanilla option prices increase with increasing volatility. This is because higher volatility means increased upside potential, yet the holder is protected from the increased downside risk by the optionality. Thus crypto options are expected to have considerably higher premiums than those on equity or FX markets.
As a few examples of the current options offerings of various exchanges:
- Binance offers American options on BTCUSDT futures with expiries from ten minutes up to one day (note that USDT is a cryptocurrency with value tethered to the USD dollar). Binance offers only ATM call and put options, that is, there is only one available strike which is equal to the most recent traded perpetual futures price.
- Deribit offers European options with a variety of strikes and one expiry per week.
- Bitmex does not currently provide options, but is keen to develop this capability.
How to price cyptocurrency options
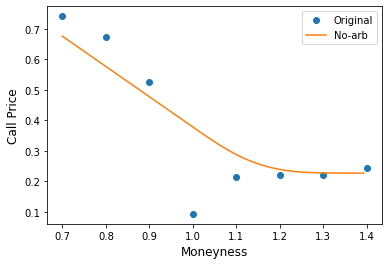
A reasonable starting point for pricing European options on cryptocurrencies is the Black-Scholes framework. In the case of American options, one can apply the binomial tree method. In either case, all of the pricing parameters such as spot and time to expiry are straight forward to determine except one – the volatility.
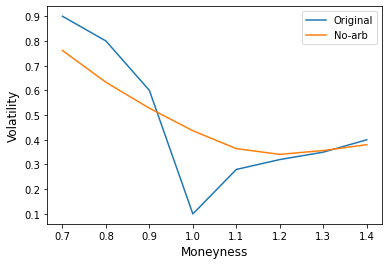
As is well-known, in developed options markets including equity, FX and interest rate options, the volatility is not really an input but is inferred from existing market prices. When calculated in this way, the volatility is inconsistent between options of differing strike and expiry, leading to a smile or volatility surface.
However, in the case of a nascent cryptocurrency options market, the market is unlikely to be sufficiently liquid, especially at the beginning, to obtain these market prices. In fact, many crypto exchanges do not allow options to be traded. Instead, the exchange functions as a market maker and simply sets the price itself.
Of course, one can always use an empirical calculation of historical volatility as a starting point, but a smile of some kind would need to be imposed upon it. One way to do this would be to start with the smile for an equity of FX rate which is believed to be in some sense similar to bitcoin, and scale it by a factor determined by taking the ratio of the equity ATM vol with the empirical volatility of the cryptocurrency.