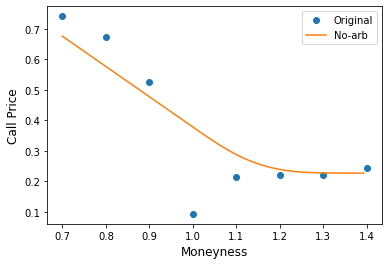
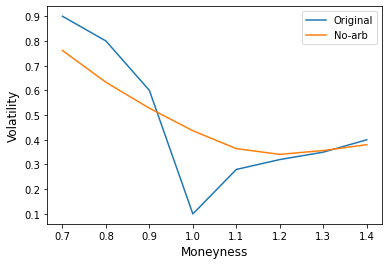
Our PhD quant consulting service can canvass the academic literature on market making models for you, and help you design, backtest and optimize your strategy. Contact us to let us know how we can supercharge your trading.
A market maker provides liquidity to the market by standing ready to both buy and sell an asset at stated bid and ask prices. They are common for both Forex markets and stock exchanges, and there are even many firms acting as market makers for bitcoin and other cryptocurrencies. The value of market making to traders is that they are able to execute trades immediately, rather than having to wait for a matching order to appear. In exchange, the market maker generates a profit by setting an appropriate spread between the bid and ask prices. A market making algorithm must determine appropriate bid and ask prices to maximise profits. There are two trade offs that a market maker must consider when trying to achieve optimal market behaviour.
Firstly, there is a trade off between volume and margin. If the market maker’s bid ask spread is too conservative, few of his trades will be fulfilled. On the other hand, if his spread is too aggressive, many trades will be fulfilled but he will make very little money from each trade. So the bid ask spread must be sufficiently attractive to other market participants while still remaining profitable for the market maker.
Secondly, while market makers can profit from the bid ask spread, they are exposed to risk due to price changes on the inventory of the asset that they must hold. If the price drops, the inventory may have to be sold at less than it was acquired for. The market maker must therefore design a quoting algorithm which optimally sets bid and ask prices to generate a profit, while also minimising inventory risk. A market maker may hope to buy and sell in approximately equal quantities to avoid accumulating a large inventory. Market making algorithms are relevant not just to genuine market makers, but to any market participant that both buys and sells an asset. One mechanism a market making algorithm can use to reduce inventory risk is to provide more conservative bid estimates when it is already long a significant inventory.
Market making strategies differ from more general trading strategies in that the latter may take on a large position based on some view of the direction the market will move in, while the market maker attempts to avoid this risky bet as much as possible.
See also our pages on optimal execution algorithms and algorithmic trading consulting services.
The Avellaneda-Stoikov model
The Avellaneda-Stoikov model is a simple market making model that can be solved for the bid and ask quotes the market maker should post at each time \(t\).
We consider the case of a market maker on a single asset with price trajectory \(S_t\) evolving under brownian motion
\[ dS_t = \sigma dW_t.\]
While this implies a normally distributed price rather than lognormally distributed, the difference is not significant over small time horizons where \(S_t\) does not move too much from its original value.
Let \(S_t^b\) and \(S_t^a\) represent the bid and ask quotes of the market maker at time \(t\), and let \(N_t^b\) and \(N_t^a\) represent the total number of market participants who have bought and sold from the market maker respectively. The model assumes that buyers arrive to purchase from the market maker at random, with an average frequency that decreases as the bid price \(S_t^b\) drops further below \(S_t\). Similarly, the frequency at which sellers arrive to sell to the market maker arrive with an average frequency that decreases as the ask price \(S_t^a\) rises further above \(S_t\). This means that the more conservatively the market maker sets his bid and ask quotes, the less likely he is to make trades.
Furthermore, the model assumes that the market maker must keep his inventory \(q_t\) between some values \(-Q\) and \(Q\). He does this by not posting a bid quote when his inventory reaches \(Q\), and similarly for an ask quote.
For simplicity, the model assumes that each buyer purchases exactly one unit. Since the market maker earns \(S_t^a\) whenever a buyer arrives, and spends \(S_t^b\) whenever a seller arrives, his cash account satisfies the equation
\[dX_t = S_t^a dN_t^a – S_t^b dN_t^b.\]
We assume that the market maker wishes to optimize his behavior over some time interval \([0,T]\). We want to find functions of time \(S_t^b\) and \(S_t^a\) which maximise the expected value of his final holdings of cash and inventory
\[X_T + q_TS_T.\]
However, in such problems it is also typical to penalise the variance of this quantity in the optimization to factor in risk aversion. One can optimize such a function using stochastic control theory. For the exact form of the solutions and for more details see The Financial Mathematics of Market Liquidity by Gueant.